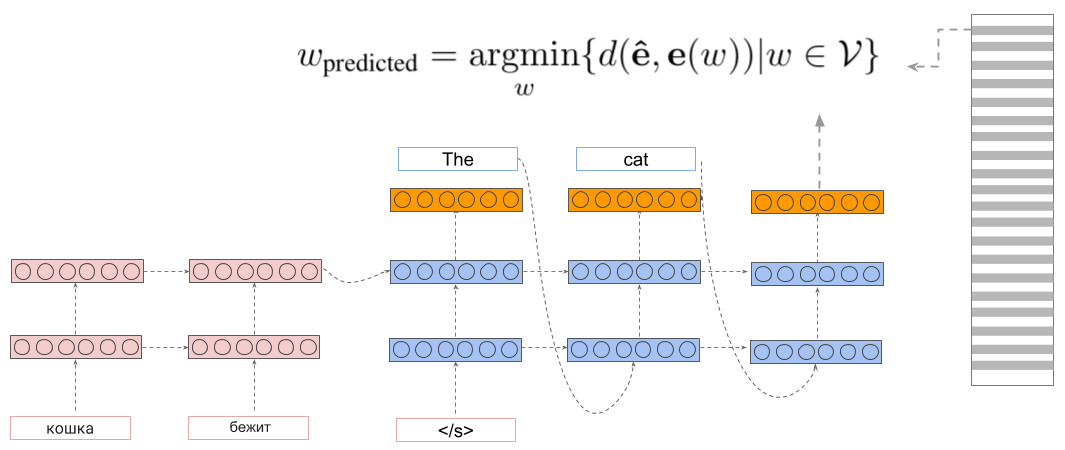
Conditional Language Generation with Continuous Outputs
The Softmax function is used in the final layer of nearly all existing sequence-to-sequence models for language generation. However, it is usually the slowest layer to compute which limits the vocabulary size to a subset of most frequent types; and it has a large memory footprint. We propose a general technique for replacing the softmax layer with a continuous embedding layer. Our primary innovations are a novel probabilistic loss and a training and inference procedure in which we generate a probability distribution over pre-trained word embeddings, instead of a multinomial distribution over the vocabulary obtained via softmax. We evaluate this new class of sequence-to-sequence models with continuous outputs on the task of neural machine translation. We show that our models obtain upto 2.5x speed-up in training time while performing on par with the state-of-the-art models in terms of translation quality. These models are capable of handling very large vocabularies without compromising on translation quality. They also produce more meaningful errors than in the softmax-based models, as these errors typically lie in a subspace of the vector space of the reference translations.
Phrase-based NMT systems with continuous-output layer
Current neural machine translation (NMT) often fails in the one-to-many translation of multi-word phrases and collocations. To tackle this problem, phrase-based NMT systems have been proposed; these typically combine word-based NMT with phrase-based statistical MT systems or external phrase dictionaries. These solutions introduce a significant overhead of additional resources and computational costs. In this project, we are working on a phrase-based NMT model built upon continuous-output NMT, in which the decoder generates embeddings of words or phrases.
End-to-End Differentiable GANs for Text Generation
Despite being widely used, text generation models trained with maximum likelihood estimation (MLE) suffer from known limitations. Due to a mismatch between training and inference, they suffer from exposure bias. Generative adversarial networks (GANs), on the other hand, by leveraging a discriminator, can mitigate these limitations. However, discrete nature of text makes the model non-differentiable hindering training. To deal with this issue, the approaches proposed so far, using reinforcement learning or softmax approximations are unstable and have been shown to underperform MLE. In this work, we consider an alternative setup where we represent each word by a pretrained vector. We modify the generator to output a sequence of such word vectors and feed them directly to the discriminator making the training process differentiable. Through experiments on unconditional text generation with Wasserstein GANs, we find that while this approach, without any pretraining is more stable while training and outperforms other GAN based approaches, it still falls behind MLE. We posit that this gap is due to autoregressive nature and architectural requirements for text generation as well as a fundamental difference between the definition of Wasserstein distance in image and text domains.
People

Sachin Kumar

Chan Young Park

Gayatri Bhat
Related Papers
- End-to-End Differentiable GANs for Text Generation, (Kumar and Tsvetkov, 2020), ICBINB
- Learning to Generate Word- and Phrase-Embeddings for Efficient Phrase-Based Neural Machine Translation, (Park and Tsvetkov, 2019), WNGT
- A Margin-based Loss with Synthetic Negative Samples for Continuous-output Machine Translation, (Bhat et al., 2019), WNGT
- Von Mises-Fisher Loss for Training Sequence to Sequence Models with Continuous Outputs, (Kumar and Tsvetkov, 2019), ICLR