Factuality Evaluation Metrics
Factuality Evaluation
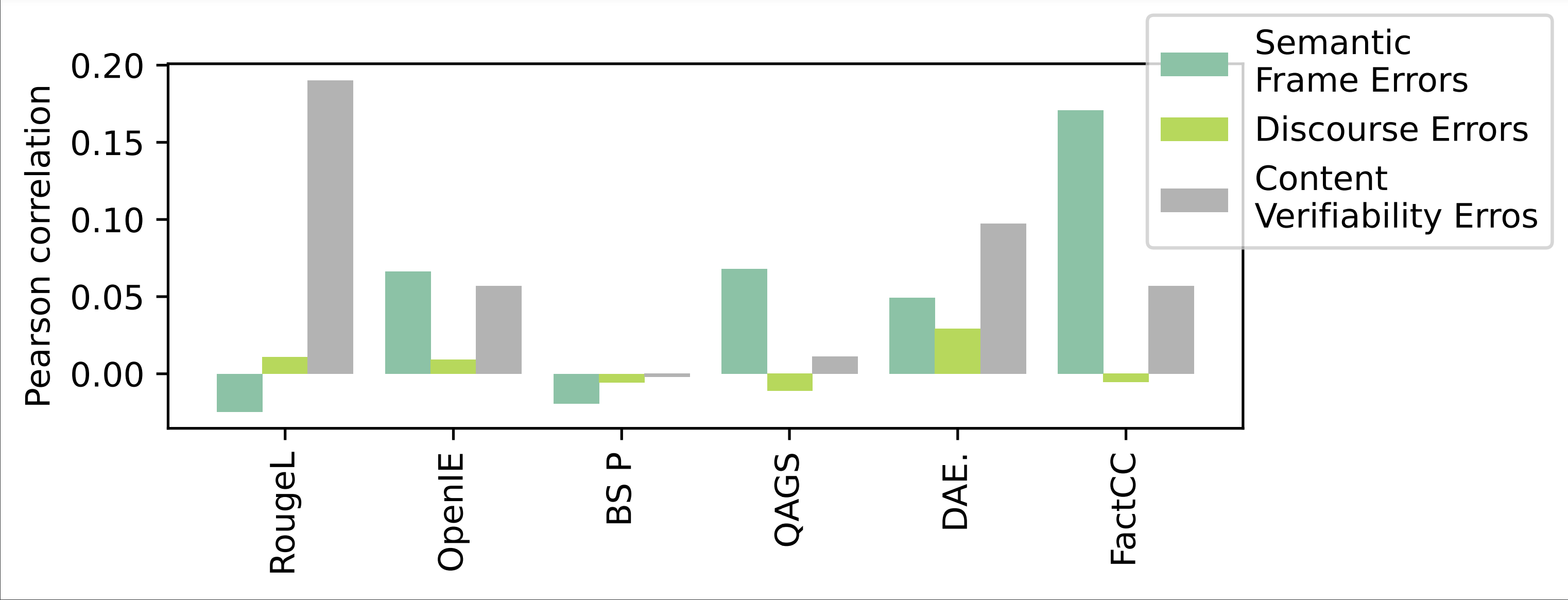
FRANK Benchmark: While there have been significant improvement in abstractive summarization, we show that recent developments have been overlooking the faithfulness of the information presented in the summaries. We first propose a linguistically grounded and operational typology of factual errors which can be used in human evaluation of summarization. We find that decomposing the concept of factuality in (relatively) well-defined and grounded categories makes the final binary decision more objective. This typology also provides us with a means to categorize the type of errors made by summarization systems helping us gain deeper insights than simply categorizing content as factual or hallucinated. The FRANK benchmark is available here and newly developed evaluation metrics can be evaluated on it. The leaderboard and analysis website is available here.
Metric Improvement: We develop a general metric for the evaluation of factuality in summarization that correlates with human judgement. Unlike prior work, our metric operates on an intermediate representation of the texts obtained by creating document level semantic graphs. The calculation of the distance between two graphs draws from the literature on embedded graphs. We evaluate our methodology with several state-of-the-art summarization models on common data sets.
People

Artidoro Pagnoni

Vidhisha Balachandran
Related Papers
- Understanding Factuality in Abstractive Summarization with FRANK: A Benchmark for Factuality Metrics, (Pagnoni et al., 2021), NAACL-HLT