End-to-End Differentiable GANs for Text Generation
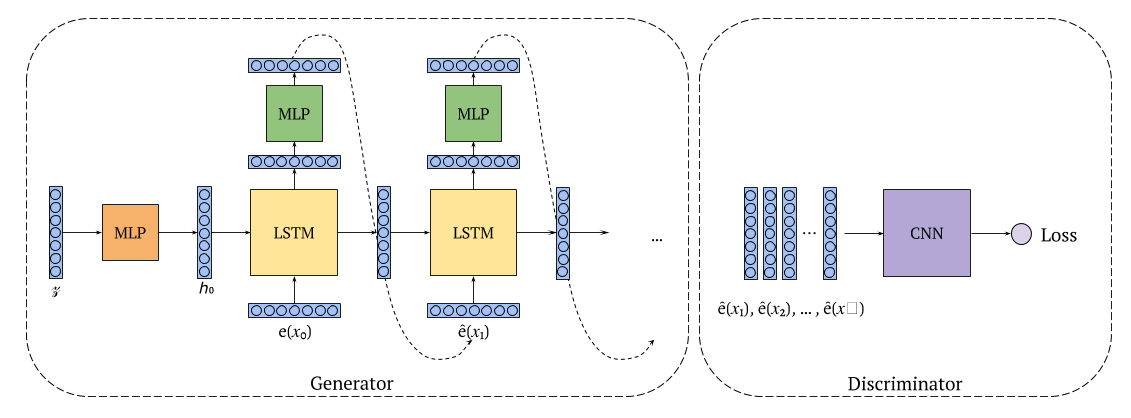
Neural language models trained with negative log likelihood are the most commonly used models for text generation. But they are known to suffer from exposure bias and the mismatch between the training and the task-specific objectives. Generative adversarial networks (GANs), on the other hand, leverage a discriminator network that learns to distinguish between real and generated data samples. However, training GANs on discrete data like text involves sampling from a vocabulary sized softmax layer to produce diverse outputs, which makes the training non differentiable. To work around this problem, prior studies used reinforcement learning or continuous approximations of softmax which are often unstable. These models work only when the generator is pretrained with a language model objective and then fine-tuned with the GAN objective with very low learning rates, suggesting the solutions remain close to the ones learned by pretraining. In this work we propose to modify the generator to output a low dimensional vector representing a word at every step and input the generated sequence of word embeddings to the discriminator making the training process differentiable and stable. This has applications in unconditional text generation as well as interpreting and controlling aspects of generated text.
People
